Introduction
As a Junior Python Developer at InterIntel Technologies Limited, I gained hands-on experience in data modeling and software development, focusing on building robust and scalable data pipelines for analytics. I leveraged open-source technologies to optimize data processing workflows, contributing to efficient, data-driven solutions that supported the company’s analytical capabilities.
Below is a summary of some of the projects i worked on.
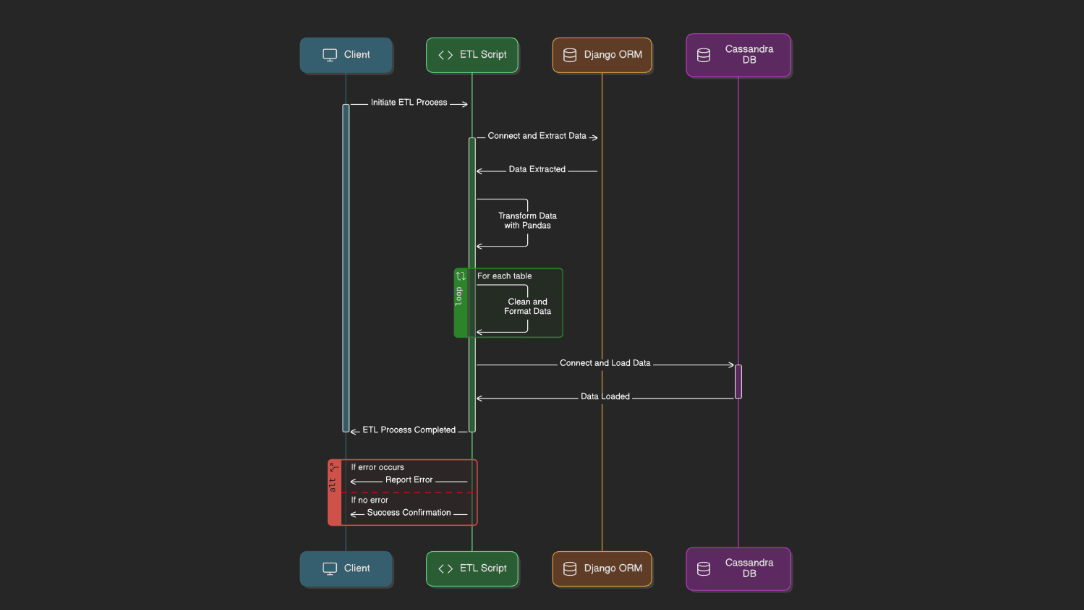
ETL Pipeline Development and Data Integration
Designed and developed efficient ETL functions, packages, and pipelines to extract, transform, and load data from multiple sources, enabling seamless data integration, and high-quality data transformations.
Automated ETL pipelines using Faust, to efficiently process, transform, and load large volumes of data for analytics.
Identified and resolved bottlenecks in SQL queries and ETL workflows to improve data retrieval and loading efficiency, significantly reducing processing times.
Key Responsibilities and Achievements
1. Pipeline design and development
- Created and documented end-to-end ETL pipelines to automate data extraction, transformation, and loading from various sources, including SQL databases, APIs and other files.
- Developed reusable ETL functions to optimize data flow and reduce processing times across the pipelines.
2. Data Extraction
- Configured connectors for data extraction from various sources including PostgreSQL, Excelsheets, CSVs etc.
- Implemented data quality and integrity checks to ensure accurate and consistent data.
3. Data Transformation
- Built robust data transformation functions to clean, standardize, aggregate and handle format conversions using pandas and Apache Spark.
4. Data Loading
- Optimized data loading processes using efficient methods such as bulk inserts, batch processing, prepared statements and asynchronous functions.
- Ensured efficient data storage through partitioning to enable faster data retrieval in cases where a cassandra database was the target database.
5. Performance Analysis
- Conducted analysis of SQL queries and ETL processes to identify inefficiencies, resource-heavy operations, and other bottlenecks causing delays in data pipelines.
6. SQL Query and ETL Workflow optimization
- Refined complex SQL queries by query restructuring, partitioning strategies and optimized JOIN operations resulting in faster data retrieval from large datasets
- Architected data loading strategies to reduce latency, leveraging batch processing and incremental loading techniques to avoid unnecessary full data loads.
Key Tech Used
- Apache Spark and Pandas for data manipulation.
- PostgreSQL and Cassandra for data storage and retrieval.
- Python, SQL and Python drivers such as Psycopgy, Cassandra cqlengine for ETL Scripting
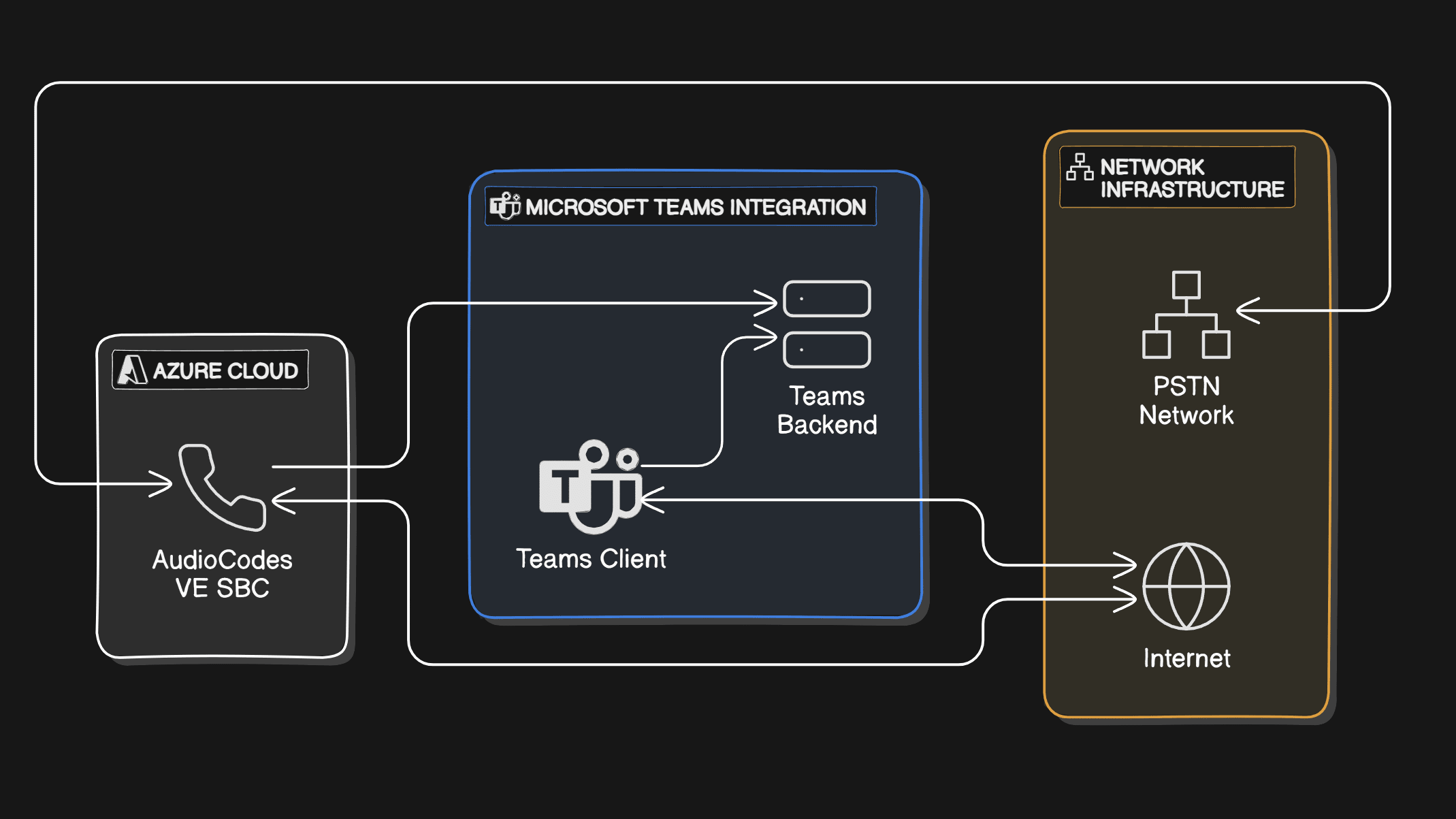
Customer Service Solution Architecture – SBC (AudioCodes VE) and Microsoft Teams Integration
Developed and implemented a robust, cloud-based customer service solution using AudioCodes Virtual Edition (VE) SBC integrated with Microsoft Teams, enabling secure, scalable, and high-quality voice communications for customer support operations.
Key Responsibilities and Achievements
1. Design and Architecture
- Created a hybrid communication framework using AudioCodes VE SBC to securely manage and route voice traffic integrating with Microsoft Teams using Direct Routing.
- Define infrastructure requirements to support seamless voice integration with Teams, ensuring compliance with security standards.
2. Microsoft Teams Integration
- Provision the correct licenses and policies required for teams users
- Set up AudioCodes VE SBC as a Direct Routing interface with Teams.
3. Security and Compliance
- Configured the SBC for secure SIP trunking with TLS/SRTP encryption, protecting voice data and meeting compliance needs for customer service.
Key Tech Used
- AudioCodes Virtual Edition (VE) for Session Border Control
- Microsoft Teams with Direct Routing and Phone System integration
- Azure Cloud for Virtual Network, Cloud infrastructure(VMs)